Bioinformatics (BI)
1. Bioinformatics 정의 및 가치
20세기 말, 인류는 인간 게놈 프로젝트를 통해 ‘생명의 설계도’라 불리는 인간의 유전 정보를 거의 모두 확보하는 데 성공했다.
약 30억 개의 염기서열로 이루어진 이 방대한 데이터는 인류 역사상 가장 큰 과학적 성과 중 하나였지만 이 성과는 단지 생명의 암호가 기록된 거대한 데이터 파일을 손에 넣은 것에 불과하다.
그 속에 담긴 의미를 해석하지 않는다면 우리는 여전히 생명의 본질과 질병의 원인을 이해하지 못한 채 남아 있게 된다.
따라서, 이러한 문제를 해결하기 위해 등장한 학문이 바로 Bioinformatics(생명정보과학) 로 이는 컴퓨터 과학, 통계학, 생물학이 융합되어 방대한 생물학적 데이터를 분석하고 생명 현상의 원리를 밝히며 질병의 메커니즘을 이해하는 핵심적인 연구 분야이다.
최근에는 Next-Generation Sequencing (NGS) 기술의 발전으로 유전체 데이터의 양이 폭발적으로 증가하고 있다.
유전체 변이, Copy Number Aberration, DNA 메틸화, 히스톤 변형, 그리고 단일세포 전사체(single-cell transcriptome) 데이터까지 다양한 생물학적 데이터가 매일 생성되고 있으며, 이러한 데이터를 분석하고 해석하는 능력은 현대 생명과학 연구의 핵심 역량이 되었다.
우리 연구팀은 이러한 대규모 생명 데이터를 분석하고 해석하여 질병의 원인을 이해하고 새로운 치료 전략을 탐색하는 연구를 수행하고 있다.
특히 암 연구 분야에서 Bioinformatics의 역할은 매우 중요하다.
우리는 유전체 데이터를 통해 종양을 유발하는 돌연변이를 찾고, 종양의 진화 과정을 이해하며, 환자 맞춤형 치료 전략을 설계하는 정밀의학(Precision Medicine) 연구를 진행중이다.
Bioinformatics는 단순한 데이터 분석 기술이 아니라 생명의 복잡한 정보를 이해하고 미래 의학을 설계하는 새로운 연구 언어이다.
2. 현재 실험실에서 수행중인 바이오 인포메틱스 탐색 연구
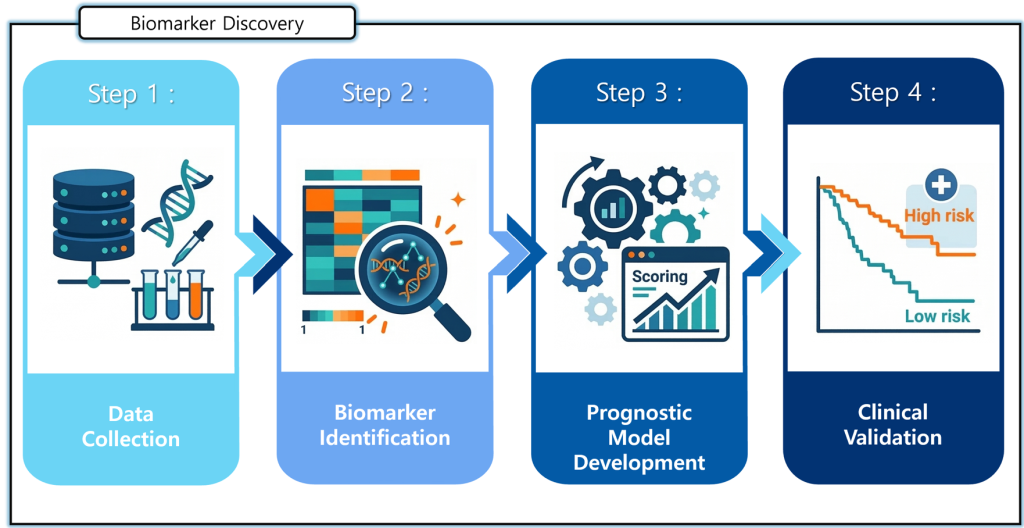
2-1) 임상 예후 예측을위 바이오마커 발굴 및 검증
왼쪽 그림은 우리 연구팀이 질병의 예후를 예측할 수 있는 바이오마커를 발굴하고, 이를 실제 의료에 활용할 수 있는지 검증하는 전체 연구 과정을 보여준다.
먼저 Data Collection 단계에서는 환자 샘플, 유전자 정보, 실험 결과 등 다양한 생물학적 데이터를 수집한다.
다음으로 Biomarker Identification 단계에서는 수집된 데이터를 분석하여 질병의 진행이나 환자의 예후와 관련된 중요한 유전자 또는 분자적 신호를 찾아낸다. 이후 Prognostic Model Development 단계에서는 이러한 바이오마커를 활용하여 환자의 질병 진행 가능성을 예측할 수 있는 예후 예측 모델을 구축한다.
마지막으로 Clinical Validation 단계에서는 개발된 모델을 실제 환자 데이터에 적용하여 환자를 고위험군과 저위험군으로 분류하고, 이 모델이 질병의 예후를 얼마나 정확하게 예측하는지를 검증한다.
이와 같은 연구를 통해 우리는 질병의 진행을 보다 정확하게 예측하고, 환자에게 더욱 적절한 치료 전략을 제시할 수 있는 새로운 바이오마커와 예측 모델을 개발하고자 한다.
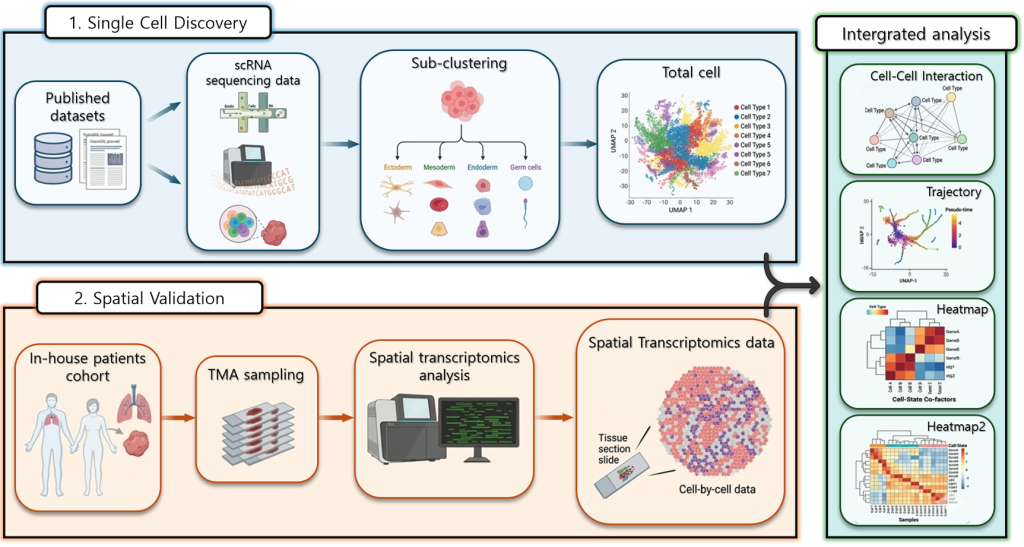
2-2) 단일세포 데이터와 공간 전사체 데이터를 통합하여 질병 조직의 세포 구성과 상호 작용을 분석하는 연구
오른쪽 그림은 단일세포 분석과 공간 전사체 분석을 함께 활용하여 질병 조직 내 세포들의 특성과 상호작용을 연구하는 전체 분석 과정을 보여준다.
먼저 Single Cell Discovery 단계에서는 공개된 단일세포 RNA 데이터를 이용하여 세포 수준의 유전자 발현 정보를 분석한다. 이를 통해 조직에 존재하는 다양한 세포들을 세부적으로 구분하고, 서로 다른 세포 유형과 그 특징을 파악한다.
다음으로 Spatial Validation 단계에서는 실제 환자의 조직 샘플을 이용하여 앞서 발견한 세포 특징이 조직 내에서 어떻게 나타나는지를 확인한다. 연구팀에서 확보한 환자 조직을 TMA 방식으로 준비한 뒤, 공간 전사체 분석을 수행하여 조직 내에서 각 세포들이 어떤 위치에 존재하는지를 파악한다. 이를 통해 세포별 유전자 발현 정보와 조직 내 공간적 분포를 함께 확인할 수 있다.
마지막으로 단일세포 데이터와 공간 분석 데이터를 통합하여 Integrated analysis를 수행한다. 이 과정에서는 세포 간 상호작용, 세포의 변화 과정(trajectory), 그리고 유전자 발현 패턴 등을 종합적으로 분석한다.
이러한 분석을 통해 조직 미세환경에서 세포들이 서로 어떻게 상호작용하며 질병이 진행되는지를 보다 깊이 이해하고자 한다..